On vectorisation of automatic adjoint C++ Code

To vectorise or not? If you ask Johannes Lotz, Klaus Leppkes, Uwe Naumann from RWTH Aachen University, Germany, the answer is an obvious yes. It provides huge improvements on modern CPUs - the best one of all: it makes run time substantially shorter. Lotz, Leppkes, and Naumann hereby share how to achieve this.
Exploitation of vectorisation capabilities in modern CPUs is crucial for getting the highest possible performance. For example, it is widely known that suitable financial Monte Carlo simulation code can benefit from vectorisation immensely. On the other hand, the efficient computation of gradients as well as of higher-order parameter sensitivities for a given (also: primal) C++ code by adjoint algorithmic differentiation (AAD) has become essential in computational finance. While auto-vectorisation built into modern compilers performs reasonably well on the primal code, it typically fails on adjoint code obtained by implementations of AAD by overloading. Vectorisation needs to be built explicitly into the corresponding AAD tools. In this article we discuss vectorised AAD by overloading based on recent advances in the upcoming version 3.4 of the AAD tool dco/c++.
Modern C++ compilers are able to automatically vectorise suitable C++ code, that is they can create vector instructions in the object code based on the results of data-dependence analysis applied to the scalar source code. This capability relies on the programmer taking care of things like data alignment and pointer aliasing. In addition, compilers can be given hints in form of vendor-specific keywords or pragmas. For example, the GNU compiler supports __builtin_assume_aligned and the OpenMP standard provides #pragma simd to mark loops operating in SIMD (single instruction multiple data) mode. The respective loop bodies need to be simple; for example, Intel suggests to use "straight-line code (a single basic block)" only and to avoid "function calls".
Vectorisation of AAD is essential unless one is willing to accept a substantial increase in run time of the adjoint code relative to the primal code. Without vectorisation and depending on the properties of the primal target code as well as on the level of maturity of the AAD solution/tool this ratio often ranges somewhere between two and ten. Failure to vectorise the adjoint can easily add an order of magnitude. The additional code complexity due to AAD implemented by operator and function overloading and possibly based on sophisticated template meta-programming methodology almost certainly prevents the compiler from auto-vectorisation as illustrated by the following image.
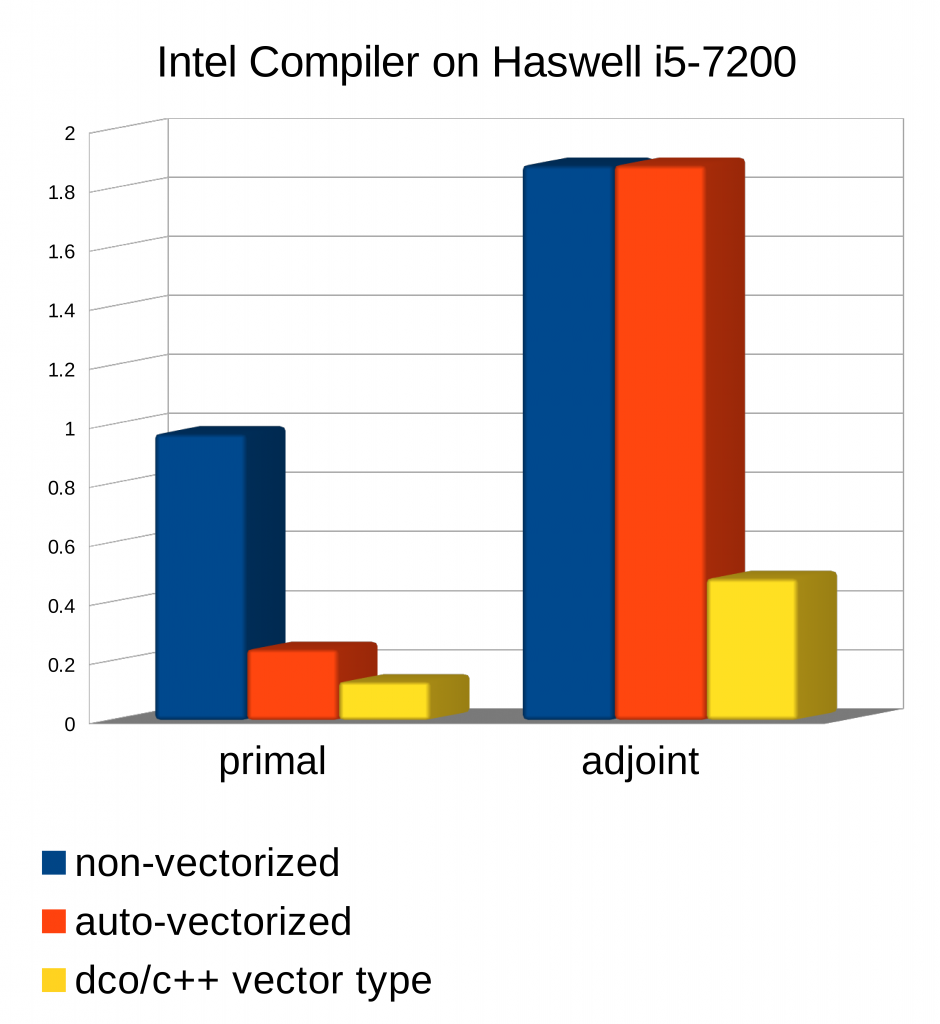
We plot absolute run times for a Monte Carlo solution of a simple stochastic differential equation compiled with the Intel C++ compiler (version 19.0) on AVX2 hardware. The relative run time of the scalar adjoint generated by dco/c++ turns out to be approximately equal to two (blue columns). Auto-vectorisation performs adequately for the primal. It fails on the adjoint (orange columns). Use of the dco/c++ vector capabilities not only regains vectorisation for the adjoint. It even decreases the primal run time (yellow columns).
Consider the following simplified Monte Carlo code for computing N paths with a set of given parameters p and random variable vector Z of matching size. The output of each individual path is stored in the vector y.

The path-wise adjoint method yields the following adjoint code with new input ya (adjoint of primal output y) and new output pa (adjoint of primal input p); only additional declarations are shown.

dco/c++ provides vector types in combination with corresponding vector instructions for use within the primal code. The SIMD length needs to be supplied as a compile time constant in form of a template argument. The memory occupied by variables of this type is required to be 32-byte aligned; a specialised allocator for std::vector comes with dco/c++. Moreover, malloc-like platform independent allocation and deallocation functions are available.

The dco/c++ vector type can be used as base type for tangent (directional) as well as adjoint derivative types yielding vectorised computation of tangents and adjoints. Recursive nesting of derivative types enables vectorised second- and higher-order tangents and adjoints. The following code shows a combination of a standard dco/c++ adjoint driver with vectorisation.

The vector types in dco/c++ are based on operator overloading making their integration into existing vectorisable code relatively straight forward. No restrictions apply to call tree depth nor to flow of control for as long as the latter does not depend on the vectorised values. Vector masking needs to be used otherwise. Refer to www.nag.com for further information on dco/c++.
Obviously, the concepts discussed in this article are not limited to implementation of AAD by overloading. Both manual and automated source transformation AAD can benefit from vectorisation. Still the ease of use of custom vector types and their seamless integration into the hierarchical AAD type system make an overloading method the preferred choice for large C++ code bases.
Watch Uwe Naumann's interview where he explains what AAD is and its significance to quantitative finance.
 This article was originally published in our eMagazine Quantitative finance in the digital age.
This article was originally published in our eMagazine Quantitative finance in the digital age.