The right way to be wrong: learning interest rate interpolation

In the previous blog post, we discussed “QLBS: Q-Learner in the Black-Scholes(-Merton) Worlds” by Igor Halperin. In this one, Halperin learns from the asset paths the option pricing and hedging functions simultaneously.
Without necessarily following the exact procedures of the paper “QLBS: Q-Learner in the Black-Scholes(-Merton) Worlds” by Igor Halperin, let’s calculate the final P&L of a hedged option portfolio.
Assuming that: (i) the option is a vanilla call with strike K and time to maturity T (ii) we bought this option and (iii) that interest rates and dividends are equal to zero, we define:
- Price of the option at the start (t=0): cK,0 = f0(S0, K, T - 0, σK, T, 0) where σ is some parameter (the reader will have guesses that this parameter should be some kind of volatility) and f is the pricing function that we want to learn
- Payoff of the option at the maturity (t=T): cK, T = max(ST - K, 0)
- The P&L of the option position at the maturity (t=T): cK, T - cK,0; we do not expect this to be zero; in fact, this will be anything but zero
- The amount of the asset chosen to hedge the option position at time t (from 0 to T - 1 day): wK, T, t = f't(St, K, T - t, σK, T, t), where f’ is the hedging function associated with the pricing function f.
- The hedged position at time t is defined as cK, t - wK, T, t St + casht; we will assume that we are always short the asset and calculate the absolute value of w
- The cash received when selling the initial hedge position: wK,T,0 S0 = f'0(S0, K, T - 0, σK, T, 0)S0
- The cashflow from the rebalancing of the hedge position at time t: (wK, T, t - wK, T, t-1)St
- The cash paid to close the last hedge position (from time T - 1 day) at time T: -wK, T, T-1St
After all that, the final P&L of the hedged portfolio can be written as:
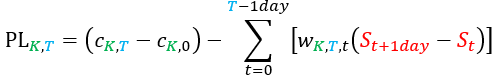
or also
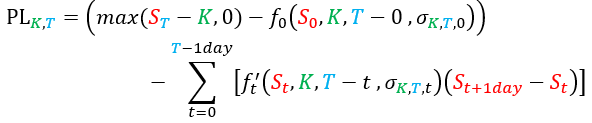
where 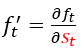
So even if we express f as some approximation or interpolation we can calculate its derivative f’, or vice-versa: if we express f’ as some approximation or interpolation, we can calculate its integral f.
Now there are two ways to look for an optimal function f / f’: You create some metric the looks at the value of the hedged portfolio during the life of the option (for that watch Alexandre Antonov present on “Quantifying Model Performance”) or you create some metric to look at the sum (with some choice of weights) of the final P&Ls of options with different Ks and Ts. Then with either choice you look for the optimal form of the function f / f’ with a choice on how to define the parametrisation of σK, T, t; if you fix f as the standard Black & Scholes formula and try to find σK, T, t you are following Dupire’s concept of the breakeven smile / volatility surface.
But who said that we need to fix f as the Black & Scholes formula? Why not try to make σK, T, t as close as possible to a value σT, t and find the best performing f, and then look at the behavior of σT, t? We know what f and f’ should look like: f is some curve that sits above the intrinsic value of the option, and therefore f’ starts at 0 and ends at 1 (looking like a sigmoid). And σK, T, t controls the slope of f’; a volatility smile enables fine control at each point of f’, but which kind of information (or insight) the smile gives us? Is there any predictive power in fixing f and using σK, T, t to fit everything?
This will be discussed at length in the Option Pricing and Volatility stream at QuantMinds International; but now we will discuss how a similar approach can be used to learn an optimal interest rate interpolation.
Assuming that: (i) we buy a zero-coupon bond with time to maturity T (ii) there are N traded zero-coupon bonds with prices pj, t maturing at times Tj and (iii) that there is an overnight funding rate rt, we define:
- Price of the bond at the start (t=0): pT, 0 = f0({pj, 0, Tj}, T - 0, M0) where M is a matrix of parameters (the reader will have guesses that this matrix should be some kind of covariance matrix) and f is the pricing function that we want to learn
- Payoff of the bond at its maturity (t=T): pT, T = 1
- The P&L of the bond position at its maturity (t= T): 1- pT, 0 ΠT-1 dayt=0 (1+ rt)1 day ; we do not expect this to be zero; in fact, this will be anything but zero
- The amount of each traded bond chosen to hedge our bond position at time t (from 0 to T - 1 day): wj, T, t = f'j, t({pj, t, Tj}, T - t, Mt), where f’ is the hedging function associated with the pricing function f.
- The hedged position at time t is defined as pT, t - ΣNj=1(wj, T, t pj, t) + casht ; we will assume that we are by default short the traded bonds and calculate (in most cases) positive values for w
- The cash received when selling the initial hedge position: ΣNj=1(wj,t, 0pj, 0) = ΣNj=1 [f'j, 0 ({pj, 0, Tj}, t = 0, M0) pj,0]
- The cashflow from the rebalancing of the hedge position at time t: ΣNj=1 [wj, T, t - wj, T, t-1 day) pj, t]
- The cash paid to close the last hedge position (from time T - 1 day) at time T: - ΣNj=1(wj, T, T-1 day pj, T-1 day)
After all that, and remembering that we now have the overnight funding rate rt to apply to every cash balance from one day to another, the final P&L of the hedged portfolio can be written as:
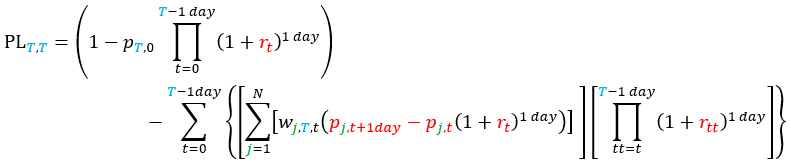
or also:
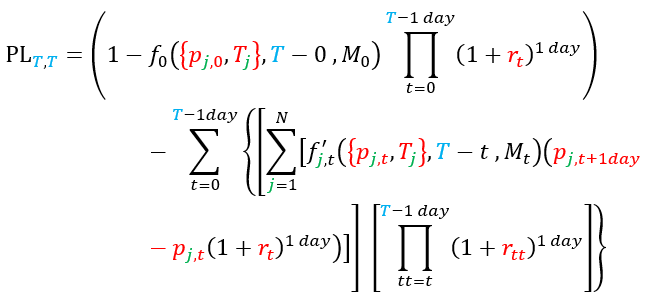
where 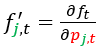
So even if we express f as some approximation or interpolation we can calculate its derivative f’, or vice-versa: if we express f’ as some approximation or interpolation, we can calculate its integral f.
The problem that we have to solve is similar to the option problem, but more things have appeared; instead of just a “volatility”, we have a “covariance” matrix; and now the joint dynamics of the overnight funding rates rt and the traded bond prices pj, t will make a difference in the final P&L.
So, instead of interpolating just the rates (or yields) of the traded bonds considering the transformation {pj, 0, Tj} → {yj, 0, Tj} and ignoring the joint dynamics of bonds and funding rates, we can try to find the best interpolation for a particular regime of volatility / Central Bank behavior.
And what is the cheat code here?
For the options case we use the smoothness of the “delta” and the peak of the time value around the spot (or forward, in more general terms) to posit a sigmoid structure for f’ and use different strikes, and the monotonicity of total variance to imply a smoother delta for longer maturities.
For bonds we can use a continuity hypothesis and a locality hypothesis (we can drop the locality later), so that weights for each traded bond are equal to 1 at the respective maturity date, 0 before and at the previous traded bond’s maturity, 0 at and after the next traded bond’s maturity date and some smooth function of time to maturity on each side of the bond:
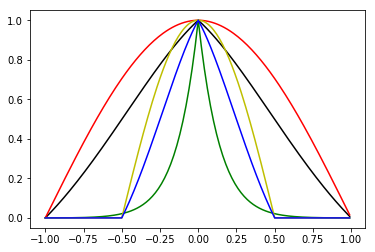
In the presentation, we’ll solve the case where each traded bond has a separate function on the left and on the right and these functions depend on a single parameter; for each time t between 0 and the maturity T of each bond there will be a list of parameters {αT, LEFT, j, t, αT, RIGHT, j, t} that will be found by minimising the sum of the PLT, T as defined above for all possible maturities T in the region where we want to learn our interpolation.
But of course there are ways to improve this method; we can use the initial results to establish some continuity between {αT, LEFT, j, t, αT, RIGHT, j, t} and {αT, LEFT, j, t+1, αT, RIGHT, j, t+1} so the learning is more robust and less dependent on particular outliers or lack of volatility. We can use deep networks for interpolation. And we expect that each attendant will figure out how to use this general concept for her particular application.
In short, our initial prices for bonds (and therefore the interpolated rates) at the beginning might seem wrong from the traditional point of view of spline / smoothness rate interpolation, but the traditional approaches say little about the relative importance of the hedge results on the overall performance of bond pricing.
More on this problem and the challenges of learning from market data (regime changes and the need for realised covariance to learn meaningful information) at the QuantMinds International conference in May.
