AI to the rescue: automatic processing of financial documents


Exposed to a mass of heterogeneous data sources, succeeding in the fund industry is increasingly about retrieving relevant information in efficient and accurate manners.
Manual processing of financial documents consumes a significant amount of time, merely to be susceptible to human errors. Not to mention that it deviates resources from more added-value activities.
In response, Deloitte has resorted to Artificial Intelligence for the heavy lifting.
Divide and conquer
When speaking of financial documents, one might have a variety in mind with widely different structures. To name a few, transaction records, financial statements, term sheets of financial instruments... It is hard to believe that a single tool could accommodate such a variety of features. Yet in the end, these documents are always composed of three elements: table, graph, and text. Extracting information from each of the three data types can be tackled with AI techniques.
Tabular data
Supplying regulatory reporting service for funds, our clients present us with workbooks containing tables as inputs. Since we wield no control over how our clients prepare their data, these tables normally have different naming conventions than our database structure. Additionally, clients tend to offer us more information than necessary, which brings more complexities to the data mapping.
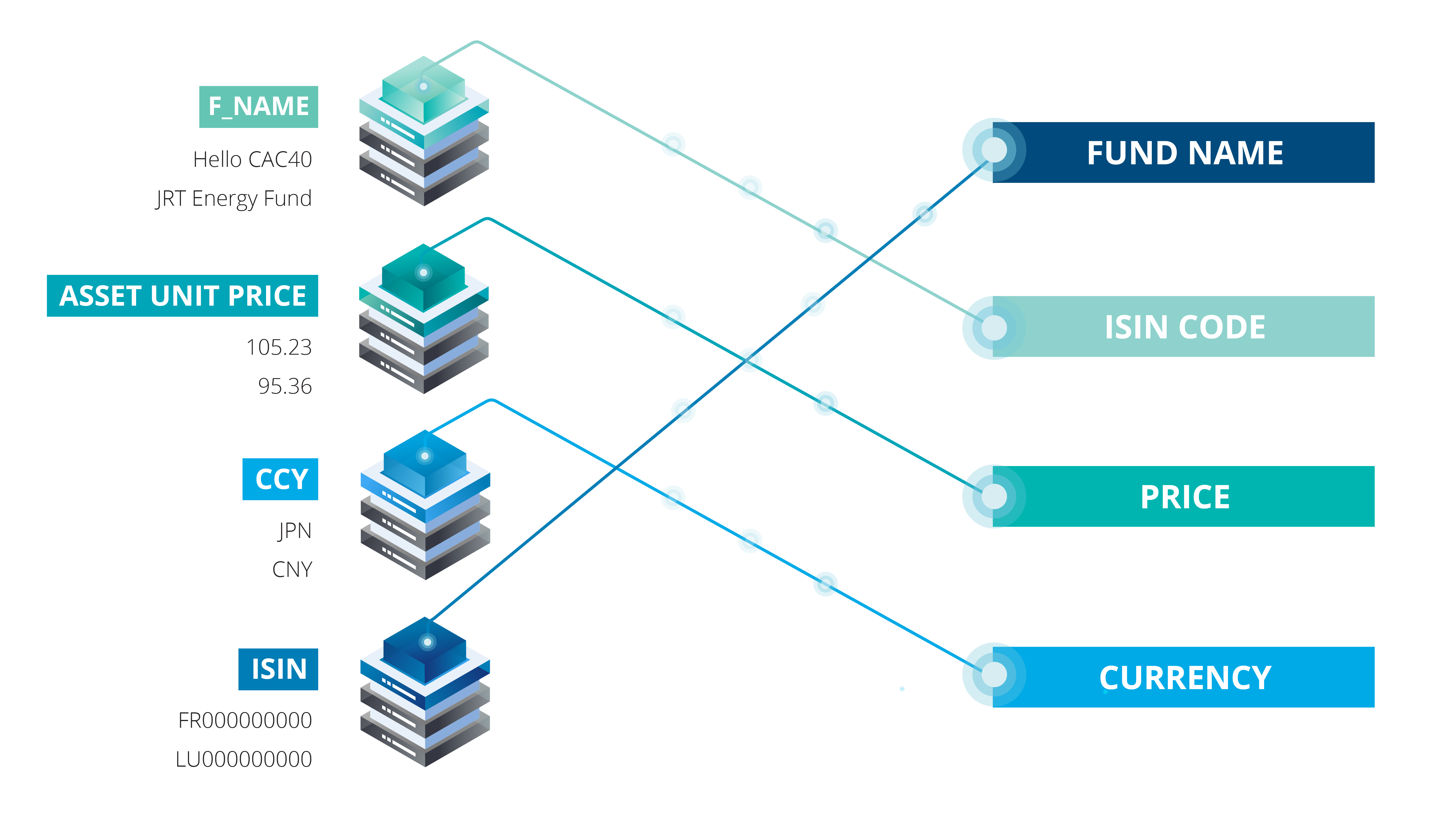
We tried to automate the data mapping using hard-coded tools within our ETL (“Extract, Transform and Load”). However, given that each data source has its own specificities, a long process is required to set-up the ETL for each of our clients. Apparently, this is far from ideal, especially as further development will be needed each time we onboard a new client.
On the other hand, machine learning approaches do not have this drawback thanks to their inherent self-adaptability. In particular, by employing supervised learning algorithms together with basic NLP methods, one can achieve a robust tool for cognitive data mapping: by analyzing the input data, the algorithm will predict what kind of data is provided and map them to their exact instance.
Note that we do not get tabular data in excel files all the time, but in documents where they are surrounded with text as well, the job of the algorithm is in this case to spot the tabular structure among the contents, i.e. to locate the headers and the data corresponding to each of the headers.
Graphic data
Have you ever been caught up in a situation where you have no other access to specific data you need, except from certain charts? In our particular case, it interests us to retrieve historical performance of a fund compared with its benchmark from the bar chart in KIIDS and store the time series in our database.
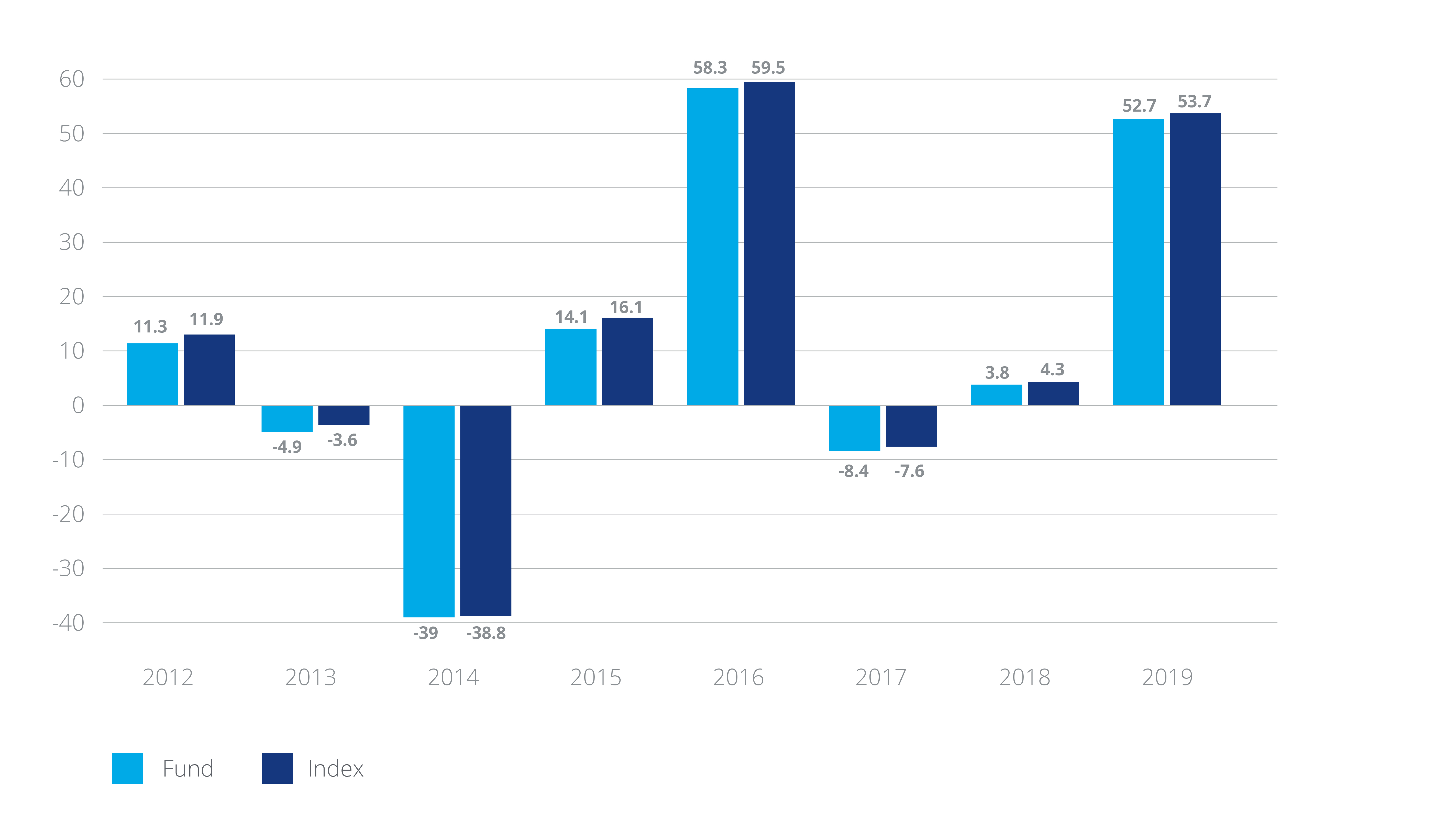
In the past, we used to carry out this task manually. As one would expect, it was not only time-consuming, but also carried more operational risk, as mistakes such as missing the decimal dot, forgetting about the minus sign, or misplacing a value in a wrong cell easily come by.
It was not before long that we started to look for an easier and steadfast way. By combining OCR that reads the figures embedded in the chart, and computer vision that validates or corrects the recognized values according to the direction and the height of the bars, we managed to precisely translate the chart into an excel table within seconds.
Similar to tabular data, most of the time, graphic data appears in a document along with texts, from which the chart object will be identified before being processed.
Textual data
Flooded with more information than ever, nowadays people no longer have the patience, nor the luxury of time to manually extract relevant information from textual documents. Imagine having to go through whole financial statements just to dig out the total value of the real estate properties.
Once a fantasy of science fiction movies, the ability for machines to interpret human language is now at the core of many applications that we use in our daily life. The underlying technique is natural language processing, which also offers solutions for automatic information extraction from textual data.
Suffering from the old way of data storage, we still need to handle documents in hard copies or scanned versions from time to time. Apart from NLP, automatic processing of these kind of documents require the involvement of computer vision.
Tools powered by AI for the automatic processing of financial documents overcome limitations of traditional approaches and offer a multitude of benefits.
- Trimmed down operating costs & operational risk: once the deployment is complete, it is instant to process a large document. Accuracy will not be compromised, by virtue of domain experts’ involvement during model training, as well as their validations on the outputs.
- Optimized resource allocation: manual processing of financial documents occupies expertise. Outsourcing to AI frees up talent, so that they can focus on core business.
- Sustained data capacity: In stark contrast to conventional methodologies, AI works better with scale. It only gets smarter and more agile as it is fed with more data. Thus, this enables organizations to keep up with explosive data growth.