Differential machine learning

AAD revolutionized both ML and finance. In ML, where it is called backpropagation, it allowed training deep neural networks (NN) in reasonable time and the subsequent success of e.g. computer vision or natural language processing. In finance, AAD computes vast numbers of differential sensitivities, with analytic accuracy and miraculous speed, giving us instantaneous model calibration and realtime risk reports of complex trading books.
AAD made differentials massively available in finance, opening a world of possibilities, of which we only scratched the surface. Realtime risk reports are only the beginning.
Recall how we produce Monte-Carlo risk reports. We first compute pathwise differentials, the sensitivities of (adequately smoothed) payoffs (sum of cashflows) wrt market variables, path by path across simulations, see this tutorial for a refresh. Then, we average sensitivities across Monte-Carlo paths to produce the risk report, collapsing a wealth of information into aggregated metrics. For example, consider a delta-hedged European call. The risk report only shows a delta of zero, from that point of view it might as well be an empty book. But before collapsing into a risk report, pathwise differentials measured the nonlinear impact of the underlying price on the final outcome in a large number of scenarios. This is a vast amount of information, from which we can e.g. extract the principal risk factors over the transaction lifetime, identify static hedges and measure their effectiveness, or learn pricing and risk function of market states on future dates.
In Danske Bank, where AAD was fully implemented in production early, the pathwise sensitivities of complex trading books are readily available for research and development of improved risk management strategies. Superfly analytics, Danske Bank’s quantitative research department, initiated a major project to train a new breed of ML models on pathwise differentials to learn effective pricing and risk functions. The trained models are capable of computing value and risks functions of the market state with near analytic speed, effectively resolving computation load of scenario based risk reports, backtesting of hedge strategies or regulations like XVA, CCR, FRTB or SIMM-MVA.
As expected, we found that models trained on differentials with adequate algorithms vastly outperform existing machine learning and deep learning (DL) methodologies.
We published a detailed description in a working paper, along with numerical results and a vast amount of additional material (mathematical proofs, practical implementation details and extensions to other ML models than NN) in online appendices. We also posted a simple TensorFlow implementation on the companion GitHub repo. You can run it on Google Colab. Don’t forget to enable GPU support in the Runtime menu.
As a simple example, consider 15 stocks in a correlated Bachelier model. We want to learn the price of a basket option as a function of the 15 stocks. Of course, the correct solution is known in closed form so we can easily measure performance. We trained a standard DL model on m simulated examples with initial state X (a vector in dimension 15) along with payoff Y (a real number), a la Longstaff-Schwartz. We also trained a differential DL model on a training set augmented with pathwise differentials Z=dY/dX, and tested performance against the correct formula on an independent dataset.
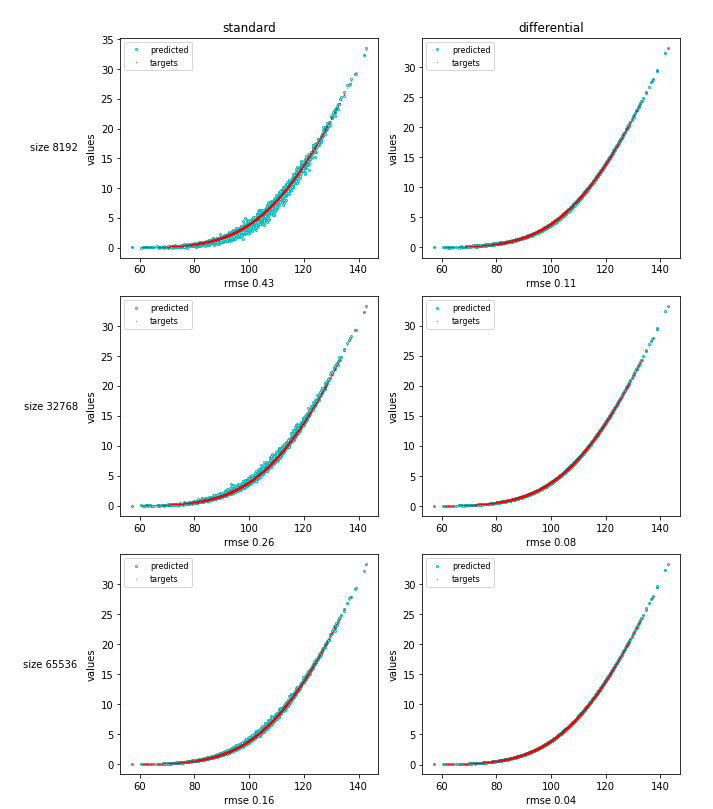
Differential training learns with remarkable accuracy on small datasets, making it applicable in realistic situations. The results carry over to transactions and simulation models or arbitrary complexity. In fact, the improvement from differential ML considerably increases with complexity. For example, we simulated the cashflows of a medium sized Danske Bank netting set, including single and cross currency swaps and swaptions in 10 different currencies in Danske Bank’s proprietary XVA model, where interest rates are simulated with a four-factor, sixteen-state multifactor Cheyette model per currency, and compared performance of a standard DL model trained on 64k paths with a differential model trained on 8k paths. Evidently, we don’t have a closed form to compare with, instead, we ran nested simulations overnight as a reference. The chart below shows performance on an independent test set, with correct (nested) values on the horizontal axis and predictions of the trained ML models on the vertical axis.
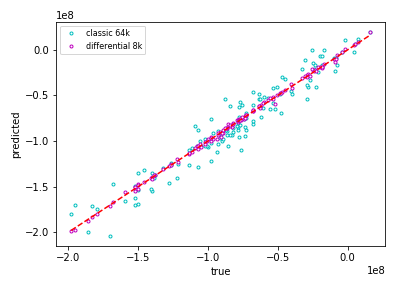
We see that differential ML achieves high quality approximation on small datasets, unthinkable with standard ML even on much bigger training sets. A correct articulation of AAD with ML gives us unreasonably effective pricing approximation in realistic time.
Besides, the core idea is very simple, and its implementation is straightforward, as seen on the TensorFlow notebook.
The trained neural net approximates the price in its output layer by feedforward inference from the state variables in the input layer. The gradient of the price wrt the state is effectively computed by backpropagation. By making backprop part of the network, we get a twin network capable of predicting prices together with Greeks.
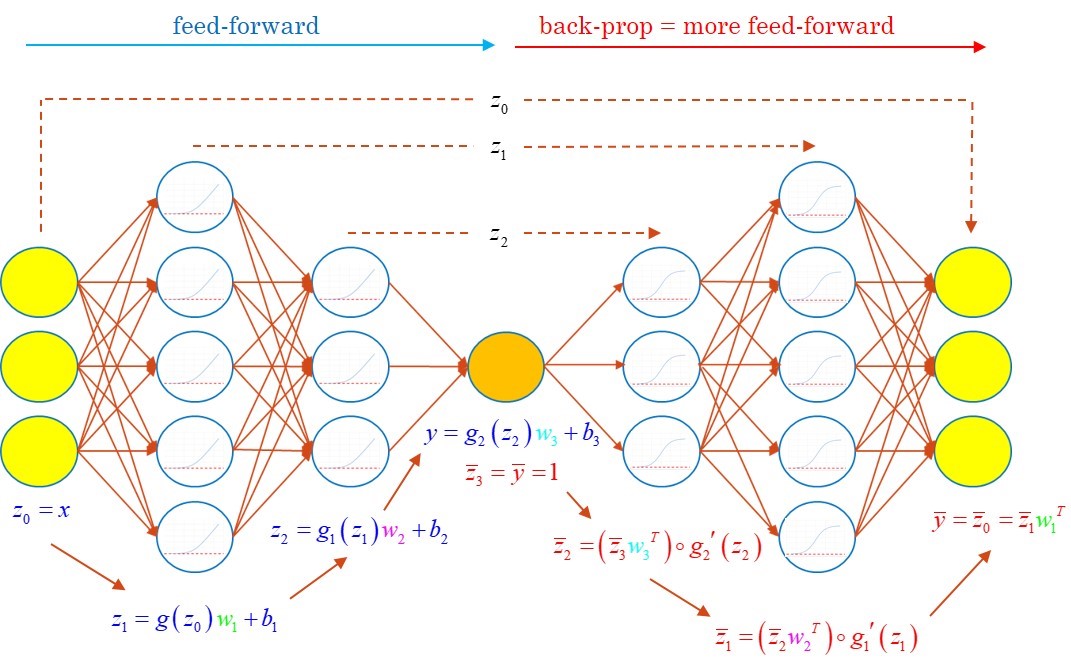
All that remains is train the twin network to predict correct prices and Greeks by minimisation of a cost function combining prediction errors on values and differentials, as compared with differential labels, a.k.a. the pathwise differentials computed with AAD:
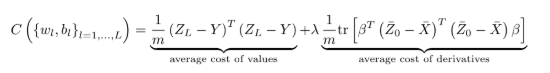
Differential training imposes a penalty on incorrect Greeks in the same way that traditional regularisation like Tikhonov favors small weights. Contrarily to conventional regularisation, differential ML effectively mitigates overfitting without introducing a bias. To see this, consider training on differentials alone. We prove in the mathematical appendix that the trained model converges to an approximation with all the correct differentials, i.e. the correct pricing function modulo an additive constant. Hence, there is no bias-variance tradeoff or necessity to tweak hyperparameters by cross validation. It just works.
Differential machine learning is more similar to data augmentation, which in turn may be seen as a better form of regularisation. Data augmentation is consistently applied e.g. in computer vision with documented success. The idea is to produce multiple labeled images from a single one, e.g. by cropping, zooming, rotation or recoloring. In addition to extending the training set for negligible cost, data augmentation teaches the ML model important invariances. Similarly, derivatives labels, not only increase the amount of information in the training set for very small cost (as long as they are computed with AAD), but also teach ML models the shape of pricing functions.
Working paper: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=3591734
Github repo: https://github.com/differential-machine-learning
About the authors
Antoine Savine and Brian Huge are affiliated with Superfly Analytics at Danske Bank, winner of the RiskMinds 2019 award Excellence in Risk Management and Modelling.
 Prior to joining Danske Bank in 2013, Antoine held multiple leadership positions in quantitative finance, including Head of Research at BNP-Paribas. He also teaches volatility and computational finance at Copenhagen University. He is best known for his work on volatility and rates, and he was influential in the wide adoption of cashflow scripting in finance. At Danske Bank, Antoine wrote the book on AAD with Wiley and was a key contributor to the bank’s XVA system, winner of the In-House System of the Year 2015 Risk award.
Prior to joining Danske Bank in 2013, Antoine held multiple leadership positions in quantitative finance, including Head of Research at BNP-Paribas. He also teaches volatility and computational finance at Copenhagen University. He is best known for his work on volatility and rates, and he was influential in the wide adoption of cashflow scripting in finance. At Danske Bank, Antoine wrote the book on AAD with Wiley and was a key contributor to the bank’s XVA system, winner of the In-House System of the Year 2015 Risk award.
 Brian works in Danske Bank quantitative research since 2001 and produced very noticeable contributions in quantitative finance with Jesper Andreasen, including the iconic ZABR: expansion for the masses, or the LVI volatility interpolation method coupled with the Random Grid algorithm, winner of the Quant of the Year 2012 Risk award. All those algorithms are implemented in Superfly, Danske Bank’s proprietary risk management platform, and used every day for the management of the bank’s trading books.
Brian works in Danske Bank quantitative research since 2001 and produced very noticeable contributions in quantitative finance with Jesper Andreasen, including the iconic ZABR: expansion for the masses, or the LVI volatility interpolation method coupled with the Random Grid algorithm, winner of the Quant of the Year 2012 Risk award. All those algorithms are implemented in Superfly, Danske Bank’s proprietary risk management platform, and used every day for the management of the bank’s trading books.
Antoine and Brian both hold PhDs in mathematics from Copenhagen University. They are regular speakers on QuantMinds and RiskMinds events.