How is reinforcement learning different from un/supervised learning?

Machine learning and artificial intelligence is becoming ubiquitous in quantitative trading. Utilising deep learning models in a fund or trading firm’s day to day operations is no longer just a concept. Compared to the more well-known and historied supervised and unsupervised learning algorithms, reinforcement learning (RL) seems to be a new kid on the block. However, it boasts with astonishing track records, solving problems after problems in the game space (AlphaGo, OpenAI Five etc.), gradually making its way to the trading world, and with a growing number of AI experts believe it to be the future of AGI (artificial general intelligence). This article serves as one of the many about how to develop and deploy reinforcement learning trading algorithms, as well as the advantages and challenges of deep RL in trading environments.
This opening article will talk about how reinforcement learning works in comparison with un/supervised learning. The goal is to explain RL in a theoretical way, using layman's terms and examples in trading. The target audience will be practitioners and quant researchers with good knowledge of machine learning, but also traders without computer science background but understand the market, risk/reward and the business of trading well. For practitioners who want to learn RL systematically, I recommend David Silver’s UCL course on YouTube, as well as the Sutton & Barto Book: Reinforcement Learning.

Fundamentally, the task of machine learning is to map a pertinent relationship between two data sets, using a function/model, which can be as simple as a linear regression with one variable, or as complex asa deep neural network with millions of parameters. In the world of trading, naturally, we want to find any generalisable relationship between a X dataset to Y target, which is future price movement, no matter how close or far into the future.
For supervised and unsupervised learning approaches, the two datasets are prepared before we train the model, or in other words, they are static. Hence, no matter how complicated the relationship the model finds, it’s a static relationship in that it represents a preset dataset. Although we have significant knowledge and experience on training and validating un/supervised deep models, this static relationship is rarely the case in the financial world. Not to mention that training models like neural networks is a global optimisation process, meaning the data 10 years ago and yesterday will have equally importance for the “AI” model in the time series, even though what really matters is next month’s performance.
At the get go, RL is different from un/supervised learning because its model is trained on a dynamic dataset to find a dynamic policy, instead of a static dataset to find a relationship. To understand how this works, we need to understand how RL is designed to be an agent-base problem in an environment. The model is represented by an agent who, by design, observes the environmental states, interacts with the environment through actions, and receives feedback in the form of rewards and state transitions (where we end up if we do this action now).
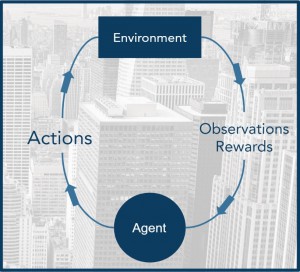
The RL model’s training data X are the experiences encountered by the agent in the form of [observation/state, action], while target data Y are the resulting reward/punishment of such action under the circumstances, in the form of [reward, next observation/state]. On a higher level, the agent is trained on its experiences to learn the best set of actions to interact with the environment, in order to get the most reward.
This training process is dynamic, referred to as on-policy learning in RL, because as the agent trains, it continues to interact with the environment and accumulate new experiences, iteratively reinforce good behaviours and diminish bad ones, and eventually solve the environment. A trained and validated RL model, therefore, is a dynamic policy rule book learned through trial and error, for a specific environment. This means an extra layer of non-linearity is added on top of the already complex neural network models widely used today, but when done right, the result is AlphaGo that is able to solve the board game Go that averages 150 steps and a total possible variation of game plays more than the number of atoms in the universe (10^360).
Mapping static relationships as in un/supervised learning have made significant progress in cognition tasks. Image recognition (Imagenet competition, iPhone facial recognition etc.) and voice/text (Siri, Alexa etc.) recognition are two major cognitive fields that we have broken through in recent years. What RL is breaking through, is the field of sequential decision-making to strategically plan, execute, and learn something also previously unique to intelligent beings.

For Go, simply recognising and remembering the limitless number of board formations does not matter unless the player knows where to place the next chip, and the hundreds of chips after to eventually win the game. This is the same for trading, knowing the past does not matter unless a trader can place his/her trades as well as allocating the right amount of risk sequentially, to eventually achieve positive NAV. This, in fact, is what RL algorithm is perfectly designed for, the next step after achieving super-human cognitive ability with un/supervised learning.
We have touched upon many underlying advantages of reinforcement learning that can apply to trading in this article.
First, the environment and agent-base design outputs a dynamic policy as opposed to a static relationship. In coming articles, we’ll discuss the inherent robustness this presents over un/supervised learning, that will be instrumental in overcoming the no.1 enemy of deep learning: overfitting.
Second, the sequential task design enables trained agents to be single end-to-end actors in the environment. For trading, we can design the environment so that it not only sequentially places and manages trades, but also trade-off near and future risk/reward through capital allocation in accordance to portfolio NAV. We’ll discuss specifically what are the tools we have in RL environments, agent actions, and reward design in the future articles.
Third, and perhaps the most importantly, the reinforcement design and on-policy learning enables agents to constantly learn and adapt to the ever-changing environment. The hardest task in trading is not about finding a strategy that works, it is about what to do when it stops working because nothing works forever. With deep neural networks, we can find any relationships that work in the historical data and validate it the traditional machine learning way. However, once deployed and things start to change, we are left with an unexplainable blackbox that is still more of an art than science to train. This is partly why deep learning is not the mainstream yet. RL by design, addresses some of these disadvantages, but it is far from a simple solution and requires tons of hard work and trial and error to realise.
In future articles, we will dive in to discuss specifics of these advantages, and the respective challenges.
Find out more about how reinforcement learning changed the game once Covid-19 struck in our latest eMagazine:

Meet Marshall Chang at QuantMinds Americas this September:

 About the author
About the author
Marshall Chang is the founder and CIO of A.I. Capital Management, a quantitative trading firm that is built on Deep Reinforcement Learning’s end-to-end application to momentum and market neutral trading strategies. The company primarily trades the Foreign Exchange markets in mid-to-high frequencies.